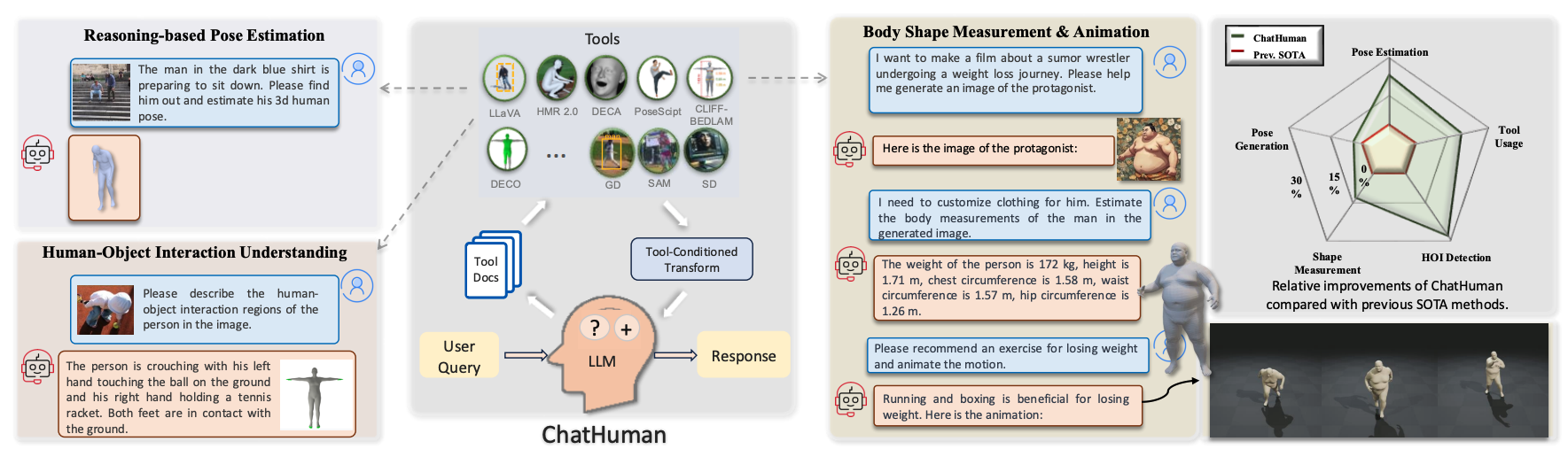
ChatHuman is a multi-modal LLM specialized for understanding humans with the assistance of tools.
Numerous methods have been proposed to detect, estimate, and analyze properties of people in images, including 3D pose, shape, contact, human-object interaction, and emotion. While widely applicable in vision and other areas, such methods require expert knowledge to select, use, and interpret the results. To address this, we introduce ChatHuman, a language-driven system that integrates the capabilities of specialized methods into a unified framework. ChatHuman functions as an assistant proficient in utilizing, analyzing, and interacting with tools specific to 3D human tasks, adeptly discussing and resolving related challenges. Built on a Large Language Model (LLM) framework, ChatHuman is trained to autonomously select, apply, and interpret a diverse set of tools in response to user inputs. Our approach overcomes significant hurdles in adapting LLMs to 3D human tasks, including the need for domain-specific knowledge and the ability to interpret complex 3D outputs. The innovations of ChatHuman include leveraging academic publications to instruct the LLM on tool usage, employing a retrieval-augmented generation model to create in-context learning examples for managing new tools, and effectively discriminating between and integrating tool results by transforming specialized 3D outputs into comprehensible formats. Experiments demonstrate that ChatHuman surpasses existing models in both tool selection accuracy and overall performance across various 3D human tasks, and it supports interactive chatting with users. ChatHuman represents a significant step toward consolidating diverse analytical methods into a unified, robust system for 3D human tasks.

@InProceedings{lin2025chathuman,
title={{ChatHuman}: Chatting about 3D Humans with Tools},
author={Lin, Jing and Feng, Yao and Liu, Weiyang and Black, Michael J.},
year={2025},
booktitle = {CVPR},
}
We thank Naureen Mahmood, Nicolas Keller and
Nicolas Heron for the support of the data collection.
Disclosure.
MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon and Meshcapade GmbH.
While MJB is a co-founder and Chief Scientist at Meshcapade, his research in this project was performed solely at, and funded solely by, the Max Planck Society.